
Why explainability and output auditing matter for product teams
What is an ai model explainability checklist? An ai model explainability checklist is a clear list of documentation, logging, and test steps that let teams explain, reproduce, and audit model outputs. Use it to verify decisions, meet regulator expectations, and reduce business risk while deploying AI features on your site.
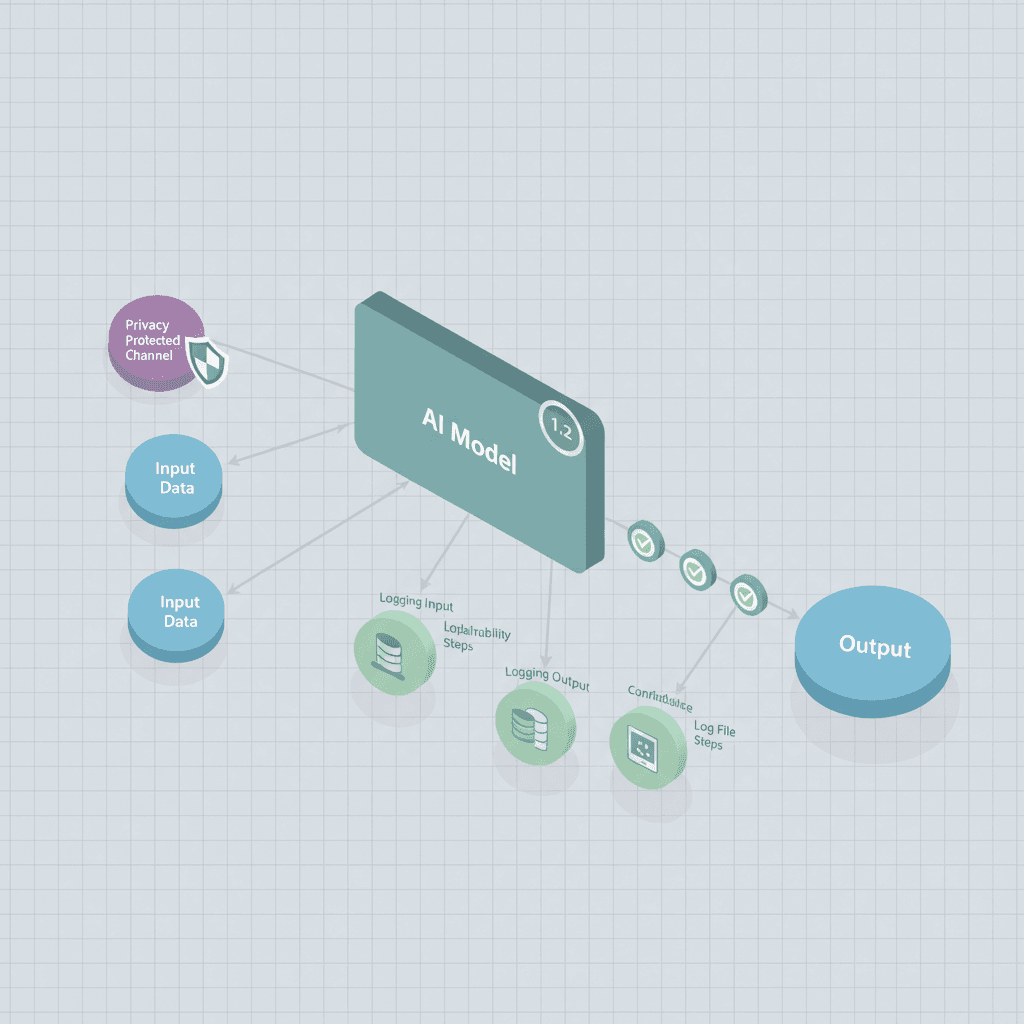
Explainability and output auditing matter because they turn opaque model behavior into actionable artifacts: model version, input hash, confidence metrics, decision rationale, and remediation steps. For product teams at marketplaces or directories like xproductlist.com, this means you can show why a recommended tool ranked higher, reproduce a surprising answer, and provide an auditable trail if a user questions a recommendation. Understanding these elements is crucial for implementing the AI product evaluation framework effectively.
Maintainables you should expect from a checklist: definitions, provenance mapping, a changelog, logging rules, privacy rules, bias checks, and an incident escalation path. Start with the primary artifacts (input, model identifier, output, metadata) and work outward toward governance and user-facing disclosures. For more on this, see Evaluate ai integration and data privacy.
Key concepts: explainability, interpretability, provenance, bias
Explainability = the ability to describe why a model produced a specific output. Provenance = the trace from input → model version → output. Interpretability is the degree a human can understand the model logic or features that drove a result. Bias refers to systematic error producing unfair outcomes for groups or contexts.
Quotable definitions: "Explainability is the ability to describe why a model produced a specific output." "Provenance is the trace of input → model version → output." These short lines are suitable for compliance notes and help when drafting an AI compliance checklist or a model card.
Regulatory cues: the EU AI Act sets higher explainability and documentation expectations for high-risk systems (see EU regulation references below), GDPR requires disclosure around significant automated decision-making in consumer-facing products in the EU/UK, and US/CA guidance emphasizes transparency for consumer-facing systems. Include these cues in your governance documents so reviewers can map artifacts to local rules.
Checklist for documenting model behavior
Document model behavior using a reproducible checklist you can apply before launch and during audits. At minimum, document the model name and snapshot, training data lineage, feature definitions, expected inputs, failure modes, and test-suite results. For xproductlist.com examples, capture the prompt template used for an LLM summary, the model provider and version, and the post-processing rules that convert raw output into a site recommendation.
Concrete checklist (copyable):
- Record model identifier and checksum (e.g., model-v1.2, SHA256).
- Store the exact input or input hash and the prompt template.
- Capture output, confidence scores, and any transformation steps.
- List known failure scenarios and example inputs that trigger them.
- Link to a changelog describing data or hyperparameter changes.
- Note retention period and legal basis for logged data.
An auditable model record ties each output to an immutable model snapshot and input hash.

| Artifact | Example | Purpose |
|---|---|---|
| Model id | open-llm-2025-03 | Reproduce output |
| Input hash | sha256:abcd... | Privacy-preserving trace |
| Prompt template | Summarize product features | Explain transformations |
| Failure examples | Missing price field | Test coverage |
Model versioning and changelogs
Version every model deployment and publish a machine-readable changelog. Each release entry should include: version tag, commit or snapshot id, training data cutoff, data preprocessing changes, and a short note on expected behavior changes. For operations, enforce a rule: never change a production model without creating a changelog entry and running the regression test suite. A simple JSON changelog record is adequate for audits.
Known limitations and intended use cases
List intended use cases and explicitly state what the model should not be used for. Example: "Intended for recommending AI tools based on feature tags; not for legal advice or financial recommendations." Also include quantitative boundaries where possible (e.g., do not accept inputs longer than 2,000 tokens; expect decreased accuracy for non-English text). These statements reduce misuse and set clear escalation criteria.
Output logging best practices
Log consistently and centrally. Use structured logs (JSON) with predictable fields so downstream auditing, monitoring, and alerting can parse them. Store logs long enough for regulatory review but short enough to satisfy privacy constraints — document your retention rationale per jurisdiction.
Operational thresholds: for latency-sensitive features, target P95 inference latency under 500ms for typical SaaS setups; record latency in the same audit record as the output. Build dashboards that surface distributional shifts in outputs and confidence scores.
Log the minimum data required to reproduce an output; do not log PII unless sanctioned by policy.
What to log (inputs, outputs, model version, confidence scores)
At a minimum log: timestamp, input hash, model id, model version, raw output, normalized output, confidence score or probability distribution, latency, and the user-facing response ID. For example, when an LLM generates a product summary for xproductlist.com, log the prompt template id, the content hash of the source product page, the model version, and the returned summary text.
Privacy-preserving logging strategies
Use hashed inputs, token redaction, or synthetic substitutes when inputs contain PII. Apply field-level encryption for sensitive fields and maintain access controls for audit logs. Store retention policy metadata with each log record and automate purging after the retention window unless a legal hold is in place.
Bias detection and fairness checks
Run bias tests during development and periodically in production. Tests should include group-level performance comparisons, disparate impact metrics, and content audits for harmful outputs. For categorical decisions, compute fairness metrics such as false positive/negative rates across demographic groups when the data allows.
Practical step: create a daily or weekly job that samples outputs, labels them for key attributes, and computes drift compared to baseline. If a metric crosses a set threshold (for example, a 10% relative increase in error for a protected group), trigger a review and rollback criteria.
Creating an audit trail for regulatory compliance
Create a searchable audit trail that links each output to its provenance: input hash, model id, changelog entry, operator actions, and test results. Include explanatory notes for automated decisions where required by law. Use the following compliance line in policies and reports: "Maintain an auditable log that links each output to model version and input hash; retain only what's necessary and document retention rationale per local law."
Map artifacts to legal obligations: EU AI Act expectations for documentation (see EU reference), GDPR automated decision disclosure requirements (see ICO guidance), and regional consumer guidance in North America. That mapping reduces reviewers' time and shows intentional governance.
Sample audit report template
Provide a concise, copyable audit report table that reviewers can use during assessments. This table captures the required fields for an output-level audit.
| Field | Example value |
|---|---|
| Report ID | audit-2026-0001 |
| Timestamp | 2026-03-15T14:22:00Z |
| Model id | open-llm-2025-03 |
| Input hash | sha256:abcd... |
| Output | Summarized product listing |
| Confidence | 0.87 |
| Reviewer notes | Output acceptable; minor fact-check required |
Human-in-the-loop patterns and escalation criteria
Design workflows where uncertain or high-risk outputs route to a human reviewer. Set quantitative triggers: confidence < 0.6, presence of flagged terms, or mismatch with external facts should escalate. Define roles (reviewer, approver) and SLAs (e.g., reviewer response within 4 business hours for user-facing escalations).
For xproductlist.com use cases, route content edits or category changes produced by a model to an editor when the model proposes modifications that alter ranking or pricing fields.
Testing explainability: unit tests, synthetic scenarios, shadow mode
Embed explainability tests into your CI pipeline. Unit tests should assert that explanation methods (feature attributions, saliency) return stable, interpretable outputs for known inputs. Use synthetic scenarios to exercise edge cases and run shadow mode in production to compare new model outputs with current production outputs without exposing users to risk.
Example test: for a given prompt template, assert that key tokens map to expected attributions and that the output format complies with downstream parsing rules.
Operationalizing remediation and user disclosures
Create playbooks for common failure modes: rollback steps, user notifications, and correction actions. Draft user-facing disclosures that explain when an automated decision was made and how to request human review. Keep disclosure language short and actionable and anchor it to your audit trail so you can respond with concrete artifacts when required.
Example: evaluating an LLM-based assistant for customer support
Run an evaluation that includes: (1) a behavior matrix mapping intents to expected answers, (2) provenance logging for each support response, (3) bias and toxic content checks, and (4) a human review pipeline for low-confidence replies. For each test ticket, capture the prompt id, model id, response text, confidence score, and reviewer decision. This replicable artifact simplifies audits and continuous improvement.
Conclusion — governance checklist and next steps
Use this ai model explainability checklist to convert ambiguous model outputs into auditable artifacts. Next steps: implement structured logging, publish a changelog, set bias detection jobs, and define human-in-the-loop SLAs. Keep the compliance line in your policies and ensure retention rationale is documented per jurisdictional law.
Quotable takeaway: "Monitoring an AI system without logging its provenance makes silent model decay indistinguishable from a production outage."
FAQ
What is explainability, logging & compliance? An ai model explainability checklist is a set of practices and artifacts—definitions, provenance records, changelogs, logs, tests, and disclosures—that let organizations explain and audit AI outputs.
How does explainability, logging & compliance work? Explainability and logging work by capturing the minimal reproducible data (input hash, model id, output, confidence), running tests to detect drift and bias, and maintaining an auditable trail that maps outputs to versions and decisions documented for reviewers.